Make Data Count¶
Make Data Count is a project to collect and standardize metrics on data use, especially views, downloads, and citations. Dataverse can integrate Make Data Count to collect and display usage metrics including counts of dataset views, file downloads, and dataset citations.
Contents:
- Introduction
- Architecture
- Limitations for Dataverse Installations Using Handles Rather Than DOIs
- Configuring Dataverse for Make Data Count Views and Downloads
- Configuring Dataverse for Make Data Count Citations
- Retrieving Make Data Count Metrics from the DataCite Hub
- Retrieving Make Data Count Metrics from Dataverse
Introduction¶
Make Data Count is part of a broader Research Data Alliance (RDA) Data Usage Metrics Working Group which helped to produce a specification called the COUNTER Code of Practice for Research Data (PDF, HTML) that Dataverse makes every effort to comply with. The Code of Practice (CoP) is built on top of existing standards such as COUNTER and SUSHI that come out of the article publishing world. The Make Data Count project has emphasized that they would like feedback on the code of practice. You can keep up to date on the Make Data Count project by subscribing to their newsletter.
Architecture¶
Dataverse installations who would like support for Make Data Count must install Counter Processor, a Python project created by California Digital Library (CDL) which is part of the Make Data Count project and which runs the software in production as part of their DASH data sharing platform.
The diagram below shows how Counter Processor interacts with Dataverse and the DataCite hub, once configured. Installations of Dataverse using Handles rather than DOIs should note the limitations in the next section of this page.
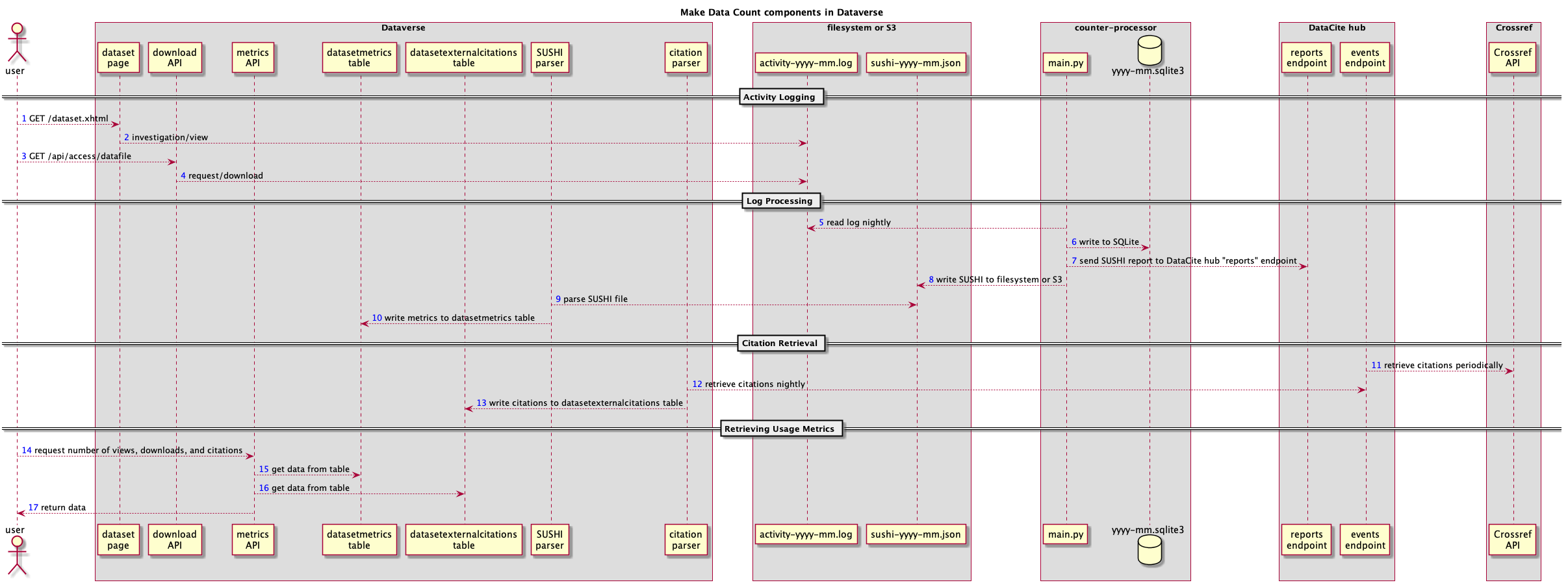
The most important takeaways from the diagram are:
- Once enabled, Dataverse will log activity (views and downloads) to a specialized date-stamped file.
- You should run Counter Processor once a day to create reports in SUSHI (JSON) format that are saved to disk for Dataverse to process and that are sent to the DataCite hub.
- You should set up a cron job to have Dataverse process the daily SUSHI reports, updating the Dataverse database with the latest metrics.
- You should set up a cron job to have Dataverse pull the latest list of citations for each dataset on a periodic basis, perhaps weekly or daily. These citations come from Crossref via the DataCite hub.
- APIs are available in Dataverse to retrieve Make Data Count metrics: views, downloads, and citations.
Limitations for Dataverse Installations Using Handles Rather Than DOIs¶
Data repositories using Handles and other identifiers are not supported by Make Data Count but in the notes following a July 2018 webinar, you can see the Make Data Count project’s response on this topic. In short, the DataCite hub does not want to receive reports for non-DOI datasets. Additionally, citations are only available from the DataCite hub for datasets that have DOIs. See also the table below.
| DOIs | Handles | |
|---|---|---|
| Out of the box | Classic download counts | Classic download counts |
| Make Data Count | MDC views, MDC downloads, MDC citations | MDC views, MDC downloads |
This being said, the Dataverse usage logging can still generate logs and process those logs with Counter Processor to create json that details usage on a dataset level. Dataverse can ingest this locally generated json.
When editing the counter-processor-config.yaml file mentioned below, make sure that the upload_to_hub boolean is set to False.
Configuring Dataverse for Make Data Count Views and Downloads¶
If you haven’t already, follow the steps for installing Counter Processor in the Prerequisites section of the Installation Guide.
Enable Logging for Make Data Count¶
To make Dataverse log dataset usage (views and downloads) for Make Data Count, you must set the :MDCLogPath database setting. See :MDCLogPath for details.
After you have your first day of logs, you can process them the next day.
Configure Counter Processor¶
- First, become the “counter” Unix user.
sudo su - counter
- Change to the directory where you installed Counter Processor.
cd /usr/local/counter-processor-0.0.1
- Download
counter-processor-config.yamlto/usr/local/counter-processor-0.0.1. - Edit the config file and pay particular attention to the FIXME lines.
vim counter-processor-config.yaml
Populate Views and Downloads for the First Time¶
Soon we will be setting up a cron job to run nightly but we start with a single successful configuration and run of Counter Processor and calls to Dataverse APIs.
- Change to the directory where you installed Counter Processor.
cd /usr/local/counter-processor-0.0.1
- If you are running Counter Processor for the first time in the middle of a month, you will need create blank log files for the previous days. e.g.:
cd /usr/local/glassfish4/glassfish/domains/domain1/logstouch counter_2019-02-01.log...touch counter_2019-02-20.log
- Run Counter Processor.
CONFIG_FILE=counter-processor-config.yaml python36 main.py- A JSON file in SUSHI format will be created in the directory you specified under “output_file” in the config file.
- Populate views and downloads for your datasets based on the SUSHI JSON file. The “/tmp” directory is used in the example below.
curl -X POST "http://localhost:8080/api/admin/makeDataCount/addUsageMetricsFromSushiReport?reportOnDisk=/tmp/make-data-count-report.json"
- Verify that views and downloads are available via API.
- Now that views and downloads have been recorded in the Dataverse database, you should make sure you can retrieve them from a dataset or two. Use the Dataset Metrics endpoints in the Native API section of the API Guide.
Populate Views and Downloads Nightly¶
Running main.py to create the SUSHI JSON file and the subsequent calling of the Dataverse API to process it should be added as a cron job.
Sending Usage Metrics to the DataCite Hub¶
Once you are satisfied with your testing, you should contact support@datacite.org for your JSON Web Token and change “upload_to_hub” to “True” in the config file. The next time you run main.py the following metrics will be sent to the DataCite hub for each published dataset:
- Views (“investigations” in COUNTER)
- Downloads (“requests” in COUNTER)
Configuring Dataverse for Make Data Count Citations¶
Please note: as explained in the note above about limitations, this feature is not available to installations of Dataverse that use Handles.
Please note that in the curl example, Bash environment variables are used with the idea that you can set a few environment variables and copy and paste the examples as is. For example, “$DOI” could become “doi:10.5072/FK2/BL2IBM” by issuing the following export command from Bash:
export DOI="doi:10.5072/FK2/BL2IBM"
To confirm that the environment variable was set properly, you can use echo like this:
echo $DOI
On some periodic basis (perhaps weekly) you should call the following curl command for each published dataset to update the list of citations that have been made for that dataset.
curl -X POST "http://localhost:8080/api/admin/makeDataCount/:persistentId/updateCitationsForDataset?persistentId=$DOI"
Citations will be retrieved for each published dataset and recorded in the Dataverse database.
For how to get the citations out of Dataverse, see “Retrieving Citations for a Dataset” under Dataset Metrics in the Native API section of the API Guide.
Please note that while Dataverse has a metadata field for “Related Dataset” this information is not currently sent as a citation to Crossref.
Retrieving Make Data Count Metrics from the DataCite Hub¶
The following metrics can be downloaded directly from the DataCite hub (see https://support.datacite.org/docs/eventdata-guide) for datasets hosted by Dataverse installations that have been configured to send these metrics to the hub:
- Total Views for a Dataset
- Unique Views for a Dataset
- Total Downloads for a Dataset
- Downloads for a Dataset
- Citations for a Dataset (via Crossref)
Retrieving Make Data Count Metrics from Dataverse¶
The Dataverse API endpoints for retrieving Make Data Count metrics are described below under Dataset Metrics in the Native API section of the API Guide.
Please note that it is also possible to retrieve metrics from the DataCite hub itself via https://api.datacite.org